- Oct 23, 2024
Comment importer des données financières dans Microsoft Fabric : Méthodes et Meilleures Pratiques
Dans le monde des données financières, la capacité à collecter, transformer et analyser les informations rapidement et avec précision est un facteur clé de succès pour les équipes comptables, de contrôle de gestion, d’audit et financières. L'arrivée de Microsoft Fabric a révolutionné ces processus en offrant une plateforme unifiée qui permet de gérer les données à grande échelle tout en intégrant des outils puissants pour l'ingestion et le traitement des informations.
Contrairement à Power BI, qui se concentrait principalement sur la visualisation et l’analyse des données, Fabric introduit une couche d’ingestion de données qui permet de capturer, stocker et traiter les données avant de les transformer en rapports exploitables. Cette architecture modulaire et flexible est particulièrement adaptée aux besoins complexes des équipes financières qui doivent traiter des données provenant de plusieurs sources, souvent volumineuses, avec des exigences de mise à jour régulières, voire en temps réel.
Dans cet article, nous explorerons les différentes méthodes d’importation de données dans Microsoft Fabric. Nous expliquerons quand et comment utiliser des outils comme les Data Flows, les pipelines de données, ou encore les shortcuts et le database mirroring. En fonction de vos besoins spécifiques — qu’il s’agisse de traiter des volumes massifs de données ou de garantir des mises à jour en temps réel — nous vous aiderons à choisir l’approche la plus adaptée pour votre équipe et vos processus métiers.
Introduction à l’importation de données dans Microsoft Fabric
1.1. Différences entre Power BI et Microsoft Fabric
Traditionnellement, les équipes financières utilisant Power BI suivaient un processus simple : connecter les sources de données via Power Query, transformer ces données, puis les utiliser directement dans des rapports ou des tableaux de bord pour la prise de décision. Ce flux de travail, bien qu’efficace, avait des limites lorsqu’il s’agissait de traiter de grandes volumétries de données, de gérer des sources multiples, ou de garantir des mises à jour fréquentes, voire en temps réel.

Avec Microsoft Fabric, l’architecture change de manière significative. Au lieu de charger les données directement dans un tableau de bord, il est nécessaire de les stocker dans Fabric avant de les utiliser pour créer des modèles et des visualisations. Cette approche introduit plusieurs avantages pour les équipes comptables, de contrôle de gestion et financières, en permettant un traitement des données plus flexible, plus rapide et surtout plus sécurisé. Cela est particulièrement pertinent dans des environnements où les données doivent circuler entre plusieurs départements, filiales ou systèmes de gestion financière.
Exemple concret :
Imaginons un scénario où une équipe de contrôle de gestion doit centraliser les données de plusieurs filiales pour la consolidation financière trimestrielle. Avec Power BI, cette tâche nécessitait l'exécution de multiples transformations à chaque mise à jour des sources, ce qui pouvait entraîner des délais et des erreurs. Avec Fabric, les données peuvent être centralisées dans un entrepôt de données Fabric, où elles sont traitées et disponibles à tout moment pour l'analyse, réduisant ainsi le risque d'erreurs et le temps nécessaire à la génération de rapports financiers précis.
1.2. Les différentes méthodes d’importation de données dans Microsoft Fabric
L'un des avantages majeurs de Microsoft Fabric est la diversité des méthodes disponibles pour importer des données. En fonction de la source de données, du volume, de la fréquence des mises à jour et de la complexité des transformations, il est possible de choisir l’outil le plus adapté. Voici un aperçu des principales options d’ingestion de données dans Microsoft Fabric :
Data Flows Gen 2 : Un outil no-code/low-code qui permet d’importer des données à partir de plus de 300 connecteurs, incluant des bases de données cloud, des fichiers Excel, et des API. Idéal pour les équipes comptables souhaitant automatiser l'importation des données depuis leurs ERP ou systèmes financiers en local via une passerelle de données.
Pipelines de données : Un outil puissant pour gérer des volumétries importantes de données et orchestrer des processus complexes. Il permet notamment de traiter les données provenant de systèmes cloud comme Azure SQL ou Azure Data Lake.
Notebooks Fabric : Pour les équipes disposant de compétences en Python, cet outil permet d’importer des données via des bibliothèques Python ou des API personnalisées, offrant une flexibilité maximale dans la gestion de l'ingestion de données.
Shortcuts et Database Mirroring : Ces outils permettent de créer des liens directs avec des fichiers ou des bases de données externes (par exemple, dans Azure Data Lake ou Amazon S3) pour garantir une mise à jour en temps réel des données sans nécessiter de processus ETL. Cela est particulièrement utile pour les équipes financières gérant des bases de données critiques en temps réel.
Exemple concret :
Une direction financière souhaitant suivre en temps réel les transactions bancaires de ses comptes peut utiliser les shortcuts pour établir un lien direct avec les fichiers stockés dans Azure Data Lake, garantissant ainsi que les rapports Power BI reflètent toujours les données les plus récentes, sans avoir à exécuter manuellement des processus d’importation ou de transformation.
Après avoir posé les bases de l’importation de données dans Microsoft Fabric, en mettant en lumière les différences clés avec Power BI et en expliquant l’importance de stocker les données avant de les exploiter, nous explorerons en détail chaque outil et ses cas d'usage.
Chaque outil d'ingestion a ses cas d'usages dans Microsoft Fabric
Choisir parmi la variété d'outils pour répondre aux différents besoins d'importation de données, nécessite de comprendre que chacun a ses avantages spécifiques en fonction de la nature des données, de la complexité des processus, et des exigences de l'équipe. Dans cette section, nous allons détailler les principaux outils disponibles pour l’ingestion de données, en expliquant comment et quand les utiliser dans un contexte financier.
2.1. Utiliser les Dataflows Gen 2 pour l'ingestion de données
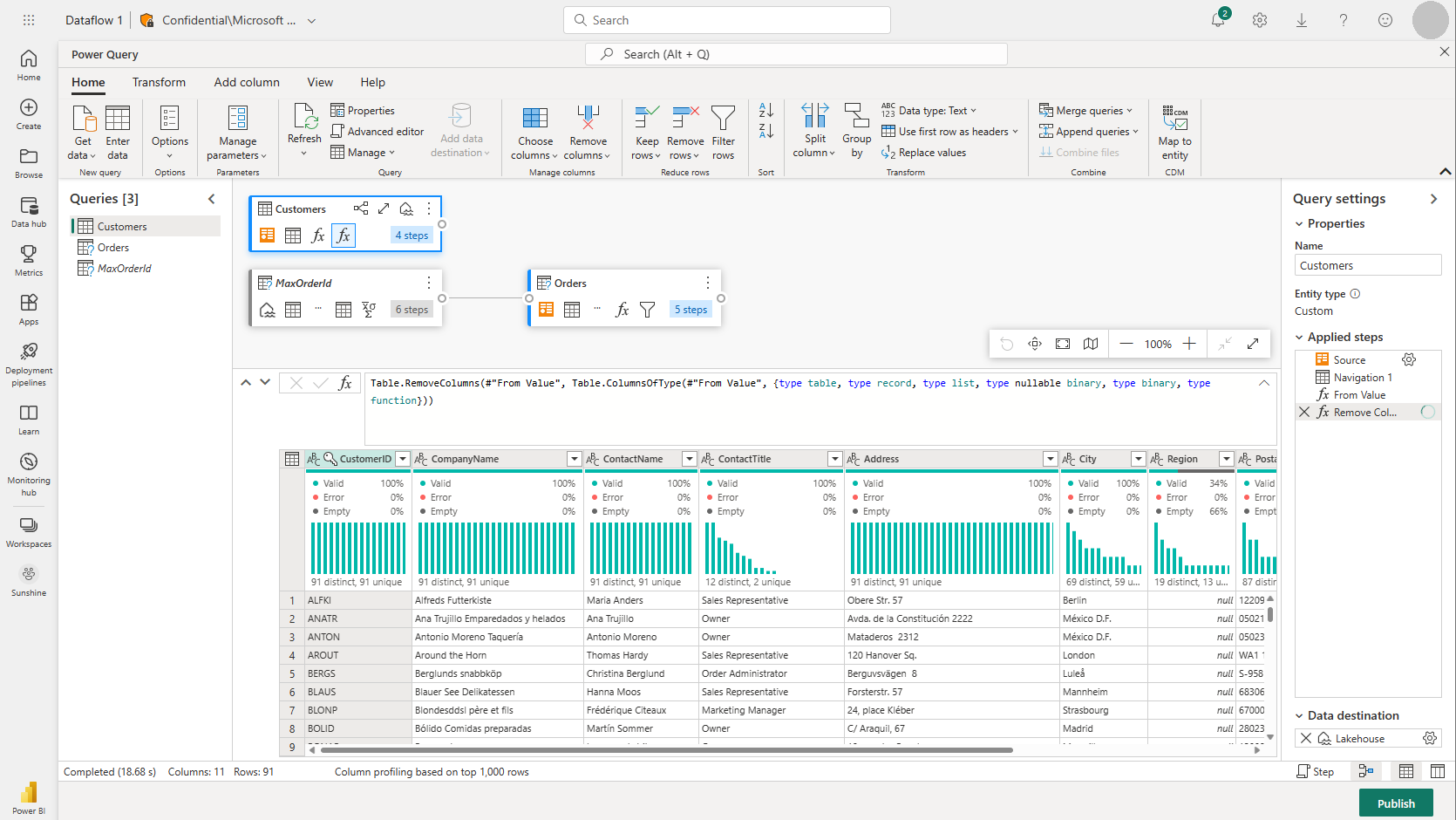
Les Dataflows Gen 2 sont l'un des outils les plus accessibles pour les utilisateurs qui ne sont pas forcément des développeurs. Ils permettent de créer des flux de données à l'aide d'une interface low-code/no-code en s'appuyant sur Power Query, ce qui est très familier pour les équipes utilisant déjà Power BI. Les Data Flows peuvent se connecter à plus de 300 sources différentes, incluant des systèmes financiers courants, des fichiers Excel, ou encore des bases de données locales via une passerelle.
Cas pratique : Centralisation des données ERP
Dans une direction financière, il est souvent nécessaire de centraliser les données provenant de différents systèmes ERP ou logiciels de gestion comptable. Par exemple, pour un contrôle budgétaire, l’équipe pourrait utiliser les Dataflows pour extraire automatiquement des écritures comptables de systèmes on-premise, via une passerelle de données, et les transformer avant de les stocker dans Fabric pour analyse. Ce processus assure une gestion fluide des flux financiers tout en réduisant les risques d'erreurs manuelles.
Limites :
Bien que puissants, les Dataflows sont moins performants lorsqu'il s'agit de traiter de très grands volumes de données, comme plusieurs gigaoctets, et peuvent être limités en termes de vérification des données avant importation. Pour des scénarios nécessitant un contrôle et une validation approfondis des données, ou des processus massifs d'importation, il est recommandé d'utiliser des outils plus robustes comme les pipelines de données.
2.2. Pipelines de données : un outil pour les grandes volumétries
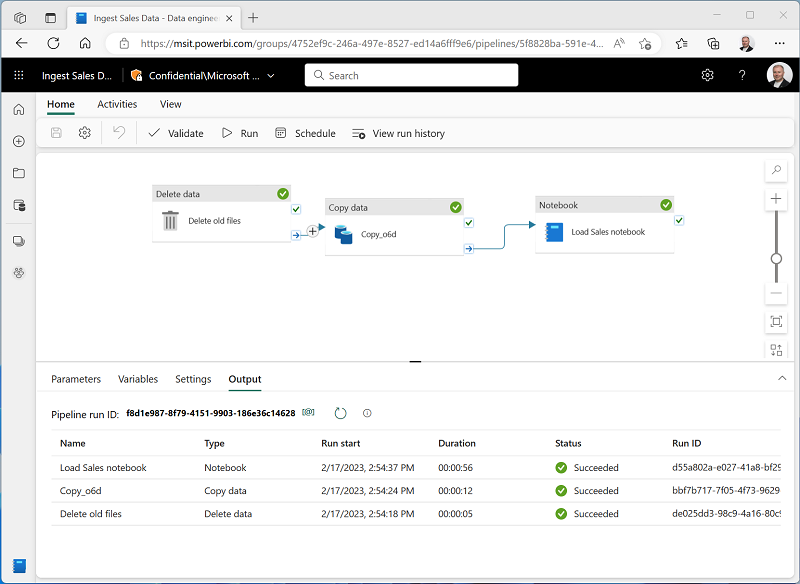
Les pipelines de données de Microsoft Fabric sont conçus pour gérer des flux de données à grande échelle et orchestrer des processus complexes, notamment en intégrant des conditions logiques ou en automatisant des séries d'activités de traitement. Cet outil est idéal pour les équipes qui doivent gérer des données provenant de plusieurs systèmes cloud, comme Azure SQL ou Azure Data Lake Storage.
Cas pratique : Consolidation financière à grande échelle
Dans un contexte de consolidation financière mondiale, une entreprise peut avoir besoin d'importer des données financières de filiales situées dans différentes régions du monde, avec des volumes importants de transactions. Les pipelines de données permettent d'orchestrer ces processus en automatisant l'importation de données de chaque filiale, tout en garantissant une gestion efficace des ressources. Par exemple, un pipeline peut être configuré pour ingérer des données mensuelles provenant de plusieurs bases de données Azure, les transformer et les charger dans un entrepôt centralisé pour l'analyse consolidée.
Limites :
Bien que puissants, les pipelines de données ne prennent pas en charge nativement la transformation des données. Si des transformations complexes sont nécessaires, il faudra intégrer un notebook ou un data flow dans le pipeline. De plus, ils ne peuvent pas encore accéder directement aux données on-premise, une limitation à prendre en compte pour les équipes travaillant avec des systèmes locaux.
2.3. Notebooks Fabric : une approche flexible avec Python
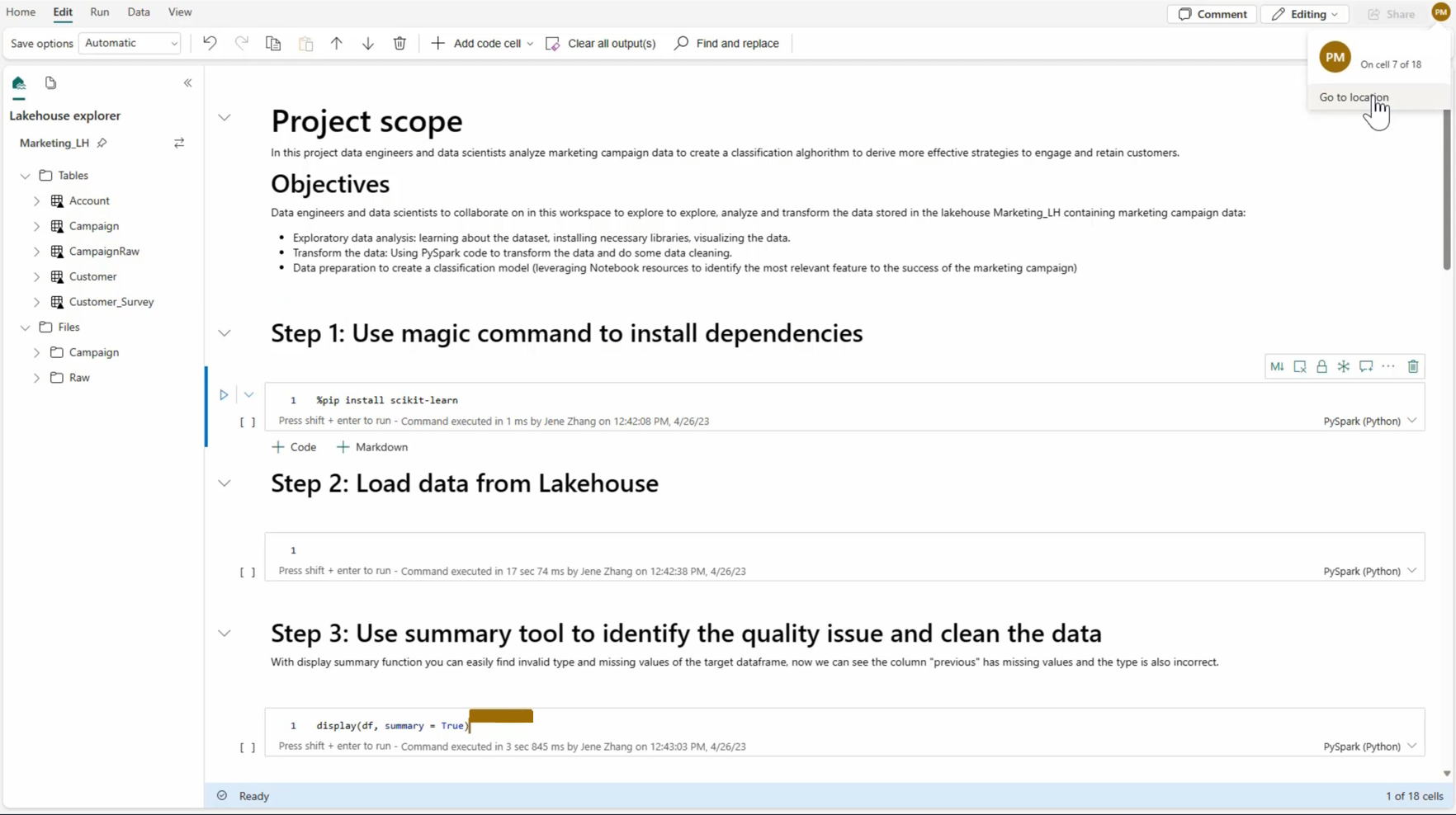
Les notebooks Fabric offrent une flexibilité maximale en permettant d’écrire du code Python pour se connecter à des APIs ou utiliser des bibliothèques Python spécifiques pour l'ingestion de données. Ils sont parfaits pour les équipes disposant de développeurs ayant des compétences en Python ou pour des cas d'usage nécessitant des traitements très personnalisés et des transformations complexes.
Cas pratique : Extraction de données API pour l'audit interne
Dans un contexte d'audit interne, l'équipe peut avoir besoin d'extraire des données financières à partir d'une API bancaire externe pour suivre en temps réel les transactions. En utilisant les notebooks Fabric, il est possible de développer une solution personnalisée en Python pour interroger cette API, automatiser l'extraction des données et valider la conformité des transactions. Ce niveau de personnalisation garantit une extraction fiable des données tout en s'adaptant aux exigences de sécurité.
Limites :
L'une des principales limites des notebooks Fabric réside dans la nécessité de compétences en Python. Si votre équipe n'a pas ces compétences, l’utilisation des notebooks peut devenir un obstacle. Pour des besoins d’ingestion plus simples ou pour des équipes non techniques, il est préférable de se tourner vers des outils low-code comme les Data Flows.
2.4. Avantages et limites des "shortcuts" et du mirroring de bases de données
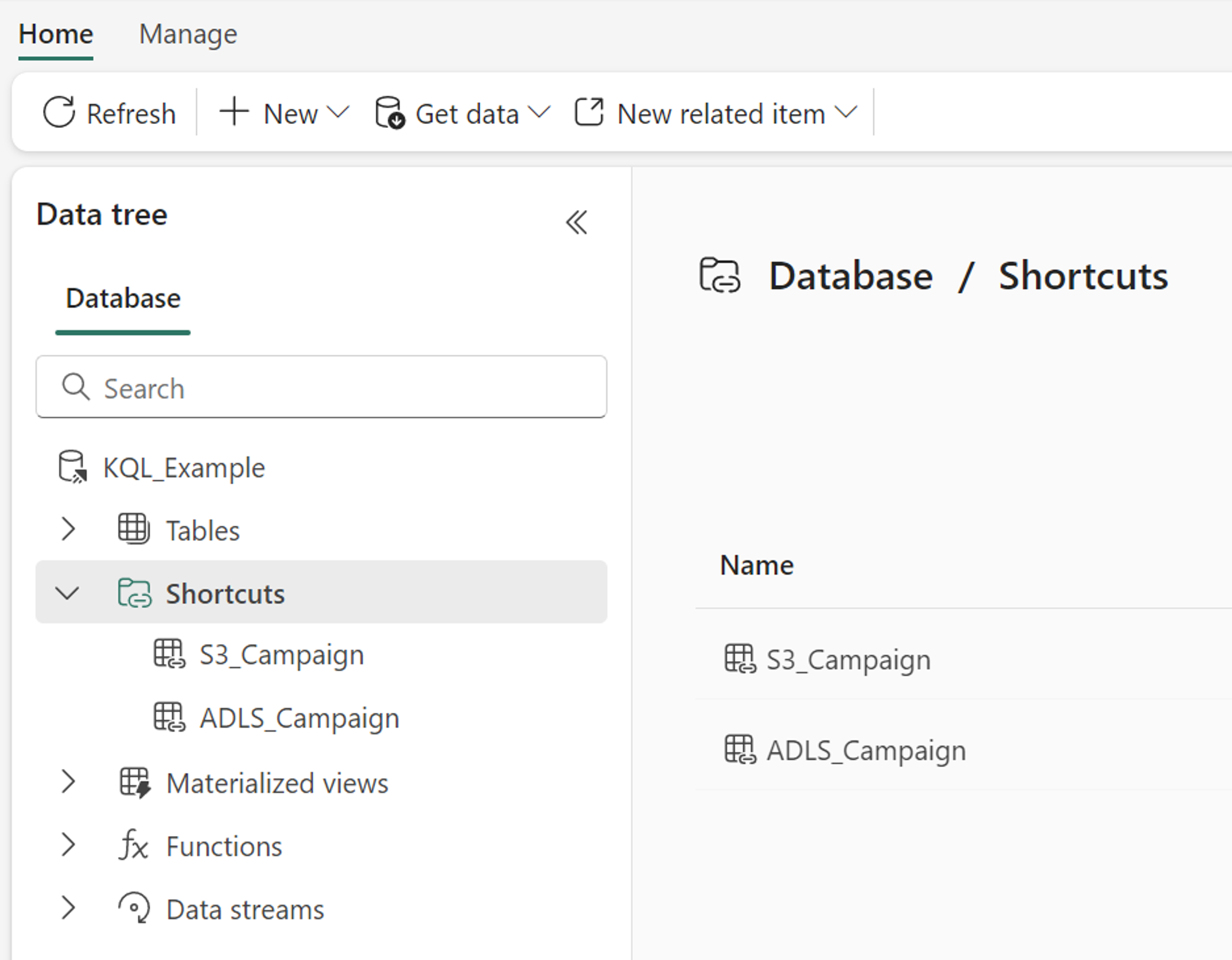
Les shortcuts permettent de créer un lien direct avec des fichiers stockés dans des systèmes externes tels qu'Azure Data Lake Storage ou Amazon S3. Contrairement aux autres méthodes qui nécessitent un processus ETL (Extract, Transform, Load), les shortcuts permettent d'accéder directement aux fichiers sans avoir à les importer manuellement dans Fabric. De plus, ces raccourcis permettent de garder les données à jour en temps réel, ce qui est particulièrement avantageux pour les équipes ayant besoin de données toujours actuelles.
De son côté, le database mirroring, encore en aperçu privé à la date de la vidéo, permettra bientôt de créer une réplication en temps réel de bases de données entières (comme Azure SQL ou Snowflake) directement dans Fabric. Cela évite les processus d'ETL manuels et garantit que les données dans Fabric reflètent toujours les dernières mises à jour des bases de données sources.
Cas pratique : Suivi des transactions bancaires en temps réel
Pour les équipes comptables et financières qui doivent surveiller en temps réel les flux de trésorerie ou les transactions bancaires, les shortcuts ou le database mirroring constituent une solution idéale. Par exemple, un shortcut vers des fichiers de transactions stockés dans Azure Data Lake permet de mettre à jour en continu les rapports Power BI sans intervention manuelle, offrant ainsi une vue en temps réel des flux financiers.
Limites :
Bien que très pratiques, les shortcuts et le database mirroring sont encore limités à certains types de fichiers et de bases de données. Par ailleurs, il est important de prendre en compte les frais d'e-transfert de données entre régions, qui peuvent s'accumuler si les fichiers source et Fabric sont situés dans des régions géographiques différentes.
Chacun des outils d’ingestion de données dans Microsoft Fabric possède ses propres forces et faiblesses. Les Data Flows sont idéaux pour les équipes souhaitant un outil low-code pour automatiser l'importation de données, tandis que les pipelines de données et les notebooks offrent des options plus puissantes pour gérer des volumes importants et des scénarios complexes. Enfin, les shortcuts et le database mirroring permettent un accès en temps réel sans les complexités liées aux processus d'ETL. Le choix de l'outil dépendra donc des spécificités de votre environnement financier, des volumes de données à traiter, et des compétences disponibles au sein de votre équipe.
Critères de choix pour la méthode d’ingestion de données
Après avoir exploré les différents outils disponibles dans Microsoft Fabric pour l’importation de données, il est essentiel de comprendre comment choisir la méthode la plus adaptée à vos besoins. Le choix dépend de plusieurs critères, notamment la nature des données, le volume, la fréquence des mises à jour, et les compétences techniques de l’équipe. Cette section vous guide à travers les principaux facteurs à considérer pour faire le meilleur choix.
3.1. Besoin de données en temps réel
L'un des critères essentiels pour déterminer la meilleure méthode d’ingestion de données est le besoin de mise à jour en temps réel. Les équipes financières, en particulier, ont souvent besoin de données à jour pour suivre des indicateurs de performance critiques, comme les flux de trésorerie ou les transactions bancaires.
Exemple pratique : Surveillance des transactions bancaires
Si vous gérez un tableau de bord pour le suivi des flux de trésorerie en temps réel, la solution idéale est d'utiliser les shortcuts ou le database mirroring. Les shortcuts vous permettent de créer des liens directs avec des fichiers stockés dans Azure Data Lake ou Amazon S3, et de maintenir ces données à jour en continu sans avoir à exécuter des processus d’importation manuelle. Le database mirroring, lorsqu’il sera disponible, permettra une mise à jour continue des données provenant de bases de données comme Azure SQL ou Snowflake, évitant les retards dus aux processus ETL classiques.
À éviter :
Les méthodes comme les pipelines de données ou les Data Flows ne sont pas recommandées dans ce contexte, car elles fonctionnent sur des programmes de mise à jour planifiés (toutes les heures, tous les jours, etc.), ce qui peut entraîner des délais dans la disponibilité des données.
3.2. Complexité et compétences au sein de votre équipe
Le deuxième critère à prendre en compte est la complexité des transformations nécessaires et les compétences disponibles au sein de votre équipe. Les outils proposés par Microsoft Fabric varient en termes de simplicité et de flexibilité, ce qui les rend plus ou moins accessibles en fonction des ressources disponibles.
Exemple pratique : Utilisation de Python pour des transformations complexes
Si votre équipe comprend des développeurs expérimentés en Python, les notebooks Fabric offriront une flexibilité maximale. Ils vous permettent de gérer des scénarios complexes, comme l’extraction de données à partir d’APIs externes (par exemple, des systèmes bancaires) et la mise en place de transformations et validations de données avancées. De plus, les notebooks facilitent l’intégration de la logique métier directement dans les processus d’ingestion.
À éviter :
Si votre équipe est plus à l’aise avec des solutions low-code ou no-code, comme Power Query, il vaut mieux privilégier les Data Flows ou les pipelines de données. Ces outils permettent d’automatiser les processus d’importation sans nécessiter de connaissances approfondies en développement, tout en offrant une interface familière pour les utilisateurs Power BI.
3.3. Capacité à gérer de grands volumes de données
Le volume de données à traiter est un autre facteur clé. Dans les départements financiers, les consolidations de données provenant de différentes filiales ou les analyses de grandes séries de transactions peuvent générer des volumétries très importantes. Tous les outils de Microsoft Fabric ne gèrent pas ces grandes quantités de données de manière optimale.
Exemple pratique : Consolidation de données financières à grande échelle
Si vous travaillez avec des volumes massifs, par exemple des millions de lignes de transactions issues de multiples filiales, les pipelines de données sont plus adaptés. Cet outil est conçu pour traiter efficacement de grandes quantités de données en les ingérant par lots, tout en optimisant l'utilisation des ressources. De plus, les notebooks utilisant Spark sont également adaptés pour des traitements de données volumineux grâce à leur capacité à paralléliser les tâches.
À éviter :
Les Data Flows peuvent montrer leurs limites lorsque vous devez manipuler de gros volumes de données régulièrement. Ils sont mieux adaptés pour des flux de données plus petits ou des mises à jour périodiques moins intensives. Si vous devez manipuler plusieurs gigaoctets de données chaque jour, l’utilisation de Data Flows pourrait être plus lente et consommer davantage de ressources.
3.4. Limites liées aux espaces de travail et à l'accès multi-espaces
Un autre point souvent négligé concerne les limitations liées aux espaces de travail dans Microsoft Fabric. Certaines méthodes d’ingestion, notamment les pipelines de données, ne permettent pas de lire ou d’écrire des données à travers plusieurs espaces de travail.
Exemple pratique : Gestion multi-espaces dans une entreprise internationale
Dans une entreprise où les données financières sont stockées dans plusieurs espaces de travail (par exemple, des espaces dédiés à chaque filiale ou à chaque région), il est essentiel de prendre en compte ces limitations. Les pipelines de données, par exemple, ne peuvent pas lire et écrire des données d’un espace à un autre. Dans ce cas, il serait plus judicieux d'utiliser des notebooks Fabric ou des shortcuts, qui permettent d’interagir avec les données provenant de plusieurs espaces de travail.
À éviter :
Si vous avez besoin de manipuler des données situées dans plusieurs espaces de travail, évitez les pipelines de données, qui ne gèrent pas bien les interactions cross-workspace. Privilégiez les notebooks ou les shortcuts qui contournent ces limitations.
3.5. Sensibilité aux coûts et à l'utilisation des capacités
Enfin, il est crucial de tenir compte de l’impact financier de chaque méthode d’ingestion, particulièrement si vous travaillez avec des volumes importants ou si vous devez exécuter fréquemment des processus de mise à jour. Les méthodes varient en termes de consommation de capacité et, par conséquent, en termes de coûts.
Exemple pratique : Optimisation des coûts pour des mises à jour fréquentes
Si vous devez exécuter des mises à jour fréquentes (par exemple, plusieurs fois par heure), il peut être plus rentable d'utiliser des shortcuts ou le futur database mirroring, car ces méthodes éliminent les besoins en capacités supplémentaires liées aux processus ETL classiques. Ces méthodes assurent une synchronisation constante des données sans avoir à réallouer des ressources pour chaque mise à jour.
À éviter :
Les méthodes comme les pipelines de données ou les Data Flows, bien qu'efficaces, consomment plus de capacité pour chaque traitement. Cela peut augmenter les coûts de manière significative si vous devez exécuter des processus d'importation fréquents ou manipuler de gros volumes de données. Avant de choisir un outil, il est conseillé de tester un petit échantillon de données pour évaluer l’impact sur les coûts et les performances.
Le choix de la méthode d’ingestion de données dans Microsoft Fabric doit être guidé par des critères spécifiques à votre contexte financier : le besoin de données en temps réel, les compétences techniques de votre équipe, la taille des données à traiter, la gestion des espaces de travail, et la sensibilité aux coûts. Chaque outil a ses forces et ses limites, et une bonne évaluation de ces facteurs vous permettra de choisir l’approche la plus adaptée à vos objectifs métier. En sélectionnant la bonne méthode, vous pourrez non seulement améliorer l’efficacité de vos processus d’ingestion de données, mais aussi garantir des performances optimales tout en maîtrisant les coûts.
Conclusion
Microsoft Fabric représente une avancée majeure pour les équipes financières, comptables et de contrôle de gestion, offrant une flexibilité et une puissance accrues pour gérer, traiter et analyser les données. En comprenant et en maîtrisant les différentes méthodes d’ingestion de données, vous pouvez non seulement optimiser vos flux de travail, mais aussi garantir une gestion plus efficace de vos ressources et de vos analyses en temps réel. Que vous gériez de grandes volumétries de données, des processus de consolidation mondiale, ou que vous ayez besoin de rapports financiers actualisés en permanence, Microsoft Fabric offre les outils nécessaires pour répondre à ces besoins de manière fluide et sécurisée.
Cependant, la clé du succès réside dans le choix de la bonne méthode d’importation de données en fonction de vos objectifs. Qu'il s'agisse d'utiliser des Data Flows pour une automatisation simple, des pipelines de données pour gérer de gros volumes, ou des shortcuts et notebooks pour garantir des mises à jour en temps réel et des traitements complexes, chaque outil présente des avantages uniques. Une bonne compréhension de ces outils vous permettra d’exploiter tout le potentiel de Microsoft Fabric pour améliorer vos processus financiers.
Vous souhaitez aller plus loin et maîtriser pleinement Microsoft Fabric ? Rejoignez notre formation spécialisée sur Microsoft Fabric dédiée aux équipes financières. Nous vous accompagnerons dans la découverte de cette plateforme, vous apprenant à utiliser chaque outil de manière stratégique pour répondre à vos besoins spécifiques.
Ce que vous apprendrez :
Comment centraliser et automatiser vos flux de données comptables et financiers.
Gérer les données en temps réel pour un reporting plus réactif.
Optimiser les coûts et les performances dans la gestion des grands volumes de données.
Personnaliser vos processus avec des notebooks et des pipelines de données.
Inscrivez-vous dès aujourd’hui et transformez la manière dont vous travaillez avec vos données financières grâce à Microsoft Fabric !
- 1 499 €
Initiation à l’analyse de données pour les métiers de la finance avec Power BI et Microsoft Fabric
- 50 Leçons